All Posts
-
[공부해서남주기] Firebase 실시간 데이터베이스 #2
안녕하세요! 웬스(ven2s)입니다. 오늘은 Firebase 실시간 데이터베이스 기본기능에 대해서 알아보려고 합니다.
일단 이 포스팅은 iOS, Swift의 기본을 어느정도 익히신분을 대상으로 작성되었습니다.
그리고 설정에 관한 부분은 공식 홈페이지가 더 잘나와 있기 때문에 별도로 작성하지 않겠습니다.
그전에 앞서서 import Firebase 를 선언해주시고
전역 변수로 아래와 같이 선언을 해주세요
var ref : FIRDatabaseReference! = FIRDatabase.database().reference()기본적인 설정인 AppDelegate.swift 파일내의 설정과 Info.plist를 프로젝트에 넣으셨다면 정상적으로 작동이 될껍니다. 만약 안된다면… 설정하는 부분을 차근히 해보시길 권장 드립니다.
다시 한번 말씀드리지만 설정에 대한 부분은 공식홈페이지가 더 자세히 나와 있으니 따로 설명은 하지 않겠습니다.
그럼 시작 해보도록 할까욧!!!
1. Firebase 실시간데이터베이스 읽기
저번 포스팅에서 언급을 했듯이 Firebase(이하 파베)는 Document형테이고 트리구조라고 말씀을 드렸습니다.
그렇기 때문에 지금 미리 선언된 ref 변수를 사용한다고 해도 전체를 가져오게 될껍니다.그래서 child([명칭]) 을 사용해서 특정 노드에 들어가 데이터를 읽고 축적을 할수 있습니다.
여기서는 Board라는 노드를 가지고 설명을 하겠습니다그래서 우리들은 아래와 같이 선언을 해주고 시작을 할껍니다.
var boardRef = ref.child("Board")위와 같이 선언을 하셔도 되고 아예처음 부터 합쳐도 괜찮습니다. 하지만 다른 노드를 호출할일이 있을지도 모르니 일단은 위에와 같이 선언하도록 합시다
자 그럼 이제 읽기에 대한 부분을 이야기 해보려고 합니다.
읽기는 기본적으로 2개의 함수를 제공을 해주는데 아래와 같습니다
//호출 func observe(_ eventType: FIRDataEventType, with block: @escaping (FIRDataSnapshot) -> Swift.Void) -> UInt //한번호출 func observeSingleEvent(of eventType: FIRDataEventType, with block: @escaping (FIRDataSnapshot) -> Swift.Void)기본적으로 파베는 비동기를 지원하고 있습니다. 그리고 FIRDataEventType 에 따라 호출될수 있도록 선언 할 수 있습니다.
또한 계속 호출 할건지 최초 한번만 호출을 할껀지까지 제공을 해주고 있습니다.
하지만 역시 주의해서 사용을 해야 합니다. 저희가 노드를 나눠서 사용을 하고 있지만 계속 추가가 되고 있다면 사용자 측면에서는 통신비가 증가 할수가 있습니다. 잘 구분해서 쓰시길 권장 드립니다.
그럼 이벤트 타입에 대해서 알아보도록 하겠습니다.
타입 설명 value 데이터 전체를 가지고 옵니다 childAdded 노드에서 부터 추가되는 데이터를 감지합니다. childRemoved 노드에서 부터 삭제되는 데이터를 감지합니다. childChanged 노드에서 부터 변경되는 데이터를 감지합니다. childMoved 노드에서 부터 이동하는 데이터를 감지합니다. 위에 같이 이벤트에 관련된 부분을 적절히 사용 하시면 됩니다. 미리 언급을 했듯이 주의 하셔야 하는 부분도 있습니다. observeSingle을 쓸것인가? observe를 쓸것인가를 잘 판단하시길 바랍니다.
일단 가장 많이 사용 되는 부분인 value 데이터를 그냥 가지고 온다고 생각하시면 됩니다. 가능하면 싱글을 사용하셔서 하시는걸 추천 드리겠습니다.
그냥 observe를 사용할 경우 계속 호출이 되는 경우가 있었기 때문에 value는 obserSingleEvent로 호출하시길 권장 드립니다(반드시는 아닙니다. 상황에 따라서는 observe를 쓰셔야 할수도 있어요)
그리고 여기서 또 언급 하고 가야 하는 부분은 FIRDataSnapshot(이하 스냅샷)일것 같습니다. 이 스냅샷은 데이터가 가져오는 형태라고 생각하시면 됩니다. 기존의 데이터베이스는 JSON으로 되어 있습니다. 스냅샷을 사용 하면 Swift에 맞도록 SDK에서 제공을 해줍니다. Dictionary타입으로 리턴이 됩니다.
let value = snapshot.value as! [String:Any]가장 좋은건 역시 break point를 걸어서 로그 커맨드라인 명령어를 통해서 확인해보시면 JSON형식으로 찍혀 있습니다. 그런데 문제는 iOS에서 가장 많이 사용 되는 Array타입으로는 변환을 하려면 어떻게 하는게 좋을까요? Enumerated 를 사용해서 변환을 하면 됩니다.
var tempList : Array<Any>! = Array() //초기화 let enumerated = snapshot.children while let rest = enumerated.nextObject() as? FIRDataSnapshot { var key = rest.key //String var dictionary = rest.value as! [String : Any] tempList.append(dictionary) }위에 코드는 Firebase 실시간데이터베이스 예제 프로젝트에서도 사용하는 방식입니다.(코드는 똑같지 않을수도 있습니다.)
이렇게 사용을 하신다면 기본적인 Dictionary 와 Array 타입으로 변환하시기 편하실껍니다. 여기서 나오는 key는 사실 중요한 부분입니다. 이부분은 이 아래 2번쨰 쓰기(저장)을 할때 다루도록 하겠습니다.
2. Firebase 실시간데이터베이스 쓰기
기존의 데이터를 저장 하기 위해서는 3가지 정도의 방법이 있습니다. 그리고 고유값을 사용하기 위해서 사용하는 메소드 총 4개가 있습니다.
메소드명 기능(혹은 용도) childByAutoId 고유값 생성 setValue 데이터를 저장할때 updateChildValues 데이터를 수정 혹은 저장 할때 runTransactionBlock 데이터를 순차적으로 저장 수정 해야 할때 (예 : 페북 좋아요) 첫째로는 childByAutoId 는 고유값을 생성을 해주는 메소드 입니다. 간단하게 말하자면 key를 생성해주는 녀석입니다. 데이터베이스를 사용하다면 특정 값을 찾기 위해서 혹은 비교하기 위해서 등의 이유로 고유키를 사용하게 됩니다 (게시판으로 치면 게시번호라고 보시면 됩니다.)
그렇기 떄문에 이 글이 중복이 나지 않게 하거나, 혹은 특정값을 찾기 혹은 증명하는 용도로 많이 사용합니다. 여기서는 key라고 부르도록 하겠습니다. (이하 key 혹은 키)
전번에도 말씀드렸듯이 Document타입인 파베 실시간데이터베이스는 트리형태의 구조를 가지고 있고, JSON 형태를 사용하고 있습니다. 그렇기 때문에 수많은 값을 증명하고 고유값을 부여해야 한다는 겁니다.
사용법은 아래와 같습니다.
let ref : FIRDatabaseReference! = FIRDatabase.database().reference().child("board") let key = ref.childByAutoId().key //String생각보다 간단합니다. (* 반드시 하나의 노드를 생성해서 사용하세요. child({노드이름}))
이제 드디어 저장을 써보도록 하겠습니다. 기본적으로 노드는 board로 잡아 놓고 시작을 하도록 하겠습니다.
let ref : FIRDatabaseReference! = FIRDatabase.database().reference().child("board") let data : [String : Any] = [ "key" : ref.childByAutoId().key, "title" : "test", "text" : "테스트로 일단 넣는 글입니다.", "recordTime" : FIRServerValue.timestamp() ] ref.setValue(data, withCompletionBlock: { (error, ref) in if let err = error { print(err.localizedDescription) } ref.observe(.value, with: { (snapshot) in guard snapshot.exists() else { return } //코드 작성 } })만약 컴플리션 블록을 안쓸 예정이라면 data 만 넣어주셔도 됩니다. (singleobserve가 아닐경우) 그리고 setValue는 업데이트를 할때도 사용이 가능합니다.
updateChildValues 에 대해서 해보려고 합니다. 함수명에서도 나와있듯이 업데이트를 할경우에 많이 사용이 되는 구문입니다. 다만 차이가 조금 있다면 아래 코드를 봅시다
let userID = FIRAuth.auth().currentUser.uid let key = ref.child("board").childByAutoId().key let post = ["uid": userID, "author": username, "title": title, "body": body] let childUpdates = ["/board/\(key)": post, "/user-posts/\(userID)/\(key)/": post] ref.updateChildValues(childUpdates)위의 코드와 같이 여러개의 노드를 동시에 해야 할경우에는 위에와 같이 사용하시면 됩니다.
여기서 중요한 부분이 있는데 실시간 데이터 베이스다 보니 여러명의 사용자가 특정 글을 수정을 하게 될경우에는 (예시 댓글 혹은 좋아요 표현) 문제가 있을수 있습니다. (실시간의 특성의 문제죠)
그렇기 때문에 runTransactionBlock을 사용 하면 됩니다. 이 함수는 순차적으로 데이터를 덮어 씌워줍니다. 그렇기 때문에 여러명이 한글에 대해서 댓글을 달거나 좋아요 표현을 할경우 순서대로 처리해줍니다.
ref.runTransactionBlock({ (currentData: FIRMutableData) -> FIRTransactionResult in if var post = currentData.value as? [String : AnyObject], let uid = FIRAuth.auth()?.currentUser?.uid { var stars : Dictionary<String, Bool> stars = post["stars"] as? [String : Bool] ?? [:] var starCount = post["starCount"] as? Int ?? 0 if let _ = stars[uid] { // Unstar the post and remove self from stars starCount -= 1 stars.removeValueForKey(uid) } else { // Star the post and add self to stars starCount += 1 stars[uid] = true } post["starCount"] = starCount post["stars"] = stars // Set value and report transaction success currentData.value = post return FIRTransactionResult.successWithValue(currentData) } return FIRTransactionResult.successWithValue(currentData) }) { (error, committed, snapshot) in if let error = error { print(error.localizedDescription) } }중요한 부분은 마지막 리턴을 해야 하는 부분을
FIRTransactionResult.successWithValue(currentData)사용해서 넣어주면 됩니다. 코드로만으로도 충분하다고 생각하기 때문에 생략하겠습니다. 코드는 개인이 작성한 코드도 있고 파베 공식부분에서도 나오는 부분을 섞어서 사용을 했습니다.어느정도 저장에 대해서 이해가 되셨는지 모르겠네요 기능 위주의 설명이다 보니 설명이 부족할 수 있습니다. Document를 참고하시거나 댓글에 추가적으로 질문을 해주셔도 됩니다.
3. Firebase 실시간데이터베이스 삭제
이번엔 삭제에 대해서 알아보려고 합니다. 완전삭제 입니다. 이부분에 대해서는 확실하게 해주고 넘어가야 겠네요 간혹 서비스의 정책으로 인해서 몇개월 혹은 몇년동안 데이터를 유지해야 할경우에는 다른 방법으로 하시고 이녀석은 정말로 데이터의 완전 삭제 입니다. 그렇기 때문에 가능하면 유저에게 알림을 통해서 완전삭제의 메세지를 통해서 복구가 안됨을 고지 하셔야 합니다.
사용법은 어렵지 않습니다
//키값이 필수이다. (단, 코드에서는 노드 위치와 고유키값을 생략함) ref.child(key!).removeValue(completionBlock: { (err, ref) in if err != nil { debugPrint("failed to remove reply") return } })위의 코드와 같이 삭제할때는 키값만 있으면 삭제가 됩니다. 그리고 확실하게 노드도 구분을 해줘야 한다. 보통은 고유키 값이라서 중복된 부분이 있을리가 만무하지만 혹모르는 일이니 꼭 노드까지 다 붙여서 사용하시길 바랍니다.
-
[공부해서남주기] Firebase 실시간 데이터베이스 #1
안녕하세요! 웬스(ven2s)입니다. 오늘은 Firebase와 NoSQL에 대해서 알아보려고 합니다.
일단 이 포스팅은 Swift에 대한 기본 지식이 조금은 있으셔야 하구요. 어느정도 XCode를 만져보셨으면 이해하시기 쉬울껍니다.
그리고 설정에 관한 부분은 공식 홈페이지가 더 잘나와 있기 때문에 별도로 작성하지 않겠습니다.
1. FIrebase?
Firebase 구글 에서 발표한지가 16년 3월정도에 발표했던 기억이 있네요. 저한테는 나름의 충격을 준 녀석입니다. 구글에서 클라우드데이터베이스 회사인 Firebase 를 인수하면서 완전히 이제는 구글 사단에 넘어간 녀석입니다. (현재는 Fabric도 인수하여 Firebase팀에 소속 되어 있습니다)
간단하게 말하자면 “서버프로그래밍이 없이 서버가 하는 역활을 수행해주는 플랫폼” 라고 생각하시면 되겠습니다.
Firebase는 여러가지 기능을 제공해줍니다. 데이터베이스, 분석, 광고, FCM(Firebase Cloud Message), 파일 저장공간등 많은 부분을 서버프로그래밍을 하지 않아도 SDK를 통해서 구현할 수 있게 도와줍니다.
그 중에서 실시간데이터베이스(Realtime Database)에 대해서 글을 써나아 가려고 합니다 .
기능에 대한 것과 설치 및 설정은 http://firebase.google.com에 가셔서 보시면 됩니다 :)
2. NoSQL
Firebase에 대해서 좀 알아보기 전에 앞서 NoSQL에 대해서 간단하게 알려드리려고 합니다. 일단은 어느정도 개발을 해보신분들이라면 MySQL, Oracle, Potgre SQL등 관계형데이터베이스 대해서 한번은 해보셨거나 안했거나 일껍니다. 주의 하셔야 할 점을 먼저 알려드리고 넘어가야겠네요
반드시!, 관계형데이터베이스를 먼제 배우신 분들은 그 개념을 NoSQL으로 적용 하지 마세요!
완전히 다른 개념으로 생각을 하셔야 접근이 쉽습니다 :)
일단 NoSQL은 간단하게 보면 비관계형데이터베이스 라고 보시면 되겠습니다. 음…그렇죠…관계형데이터베이스를 반대되는 개념…..근데…좀…뭔가가….
부가적으로 말하자면 스키마가 없는 데이터베이스입니다. (* 스키마란? Table, Column 과 같은 데이터베이스를 구성하는 도식(설계) 혹은 구성을 말합니다. )
스키마가 없는 데이터베이스이기 때문에 테이블을 구성하는 스키마 혹은 컬럼의 자료형 등 규칙이 따로 없습니다. 덕분에 확장성 용이 합니다. 관계형데이터베이스 기준으로는 스키마를 바꾸게 되면 필요한 작업을 해야 하고 데이터에 대한 마이그레이션을 진행해야 합니다.(데이터가 많이 있다면 어휴…) 하지만 NoSQL은 스키마가 없기 때문에 그냥 새로운 컬럼이 있으면 데이터를 넣기만 하면 됩니다.
전반적으로 봤을때 NoSQL은 기존의 관계형데이터베이스가 가진 단점을 보완한 형태라고 생각하시면 됩니다. 최근에는 빅데이터 시대가 되면서 이를 저장하는 데이터베이스도 기존의 형태와는 달라야 했기 때문입니다. 그리고 괸라를 용이하게 하기 위한 분산처리와 데이터의 안정성을 위해서 개발이 되었습니다.
그렇기 떄문에 관계형데이터베이스 관점에서 보게 된다면 더 어려운 개념으로 보시게 될껍니다.
NoSQL 뭐 명칭에 대해서는 Not Only SQL이다 말 그대로 No SQL이다. 말들이 있지만 하지만 제 생각에는 NoSQL인거 같습니다. (정식적으로는 Not Only SQL입니다.), SQL말고도 더 있는 부분이 있습니다.
NoSQL의 종류와 데이터베이스
종 류 특 징 데이터베이스 Key-Value 가장 기본적, 범위검색 힘듬 다이나모, 리악, 레디스, 캐시, 프로젝트 볼드모트 Column 키-값에서 확장되어 한개의 컬럼에 여러개를 저장 할수 있음 H베이스, 아큐물로 Document JSON, XML과 같은 형식을 사용 Firebase, MongoDB, CoauchDB Graph 좀더 유연한 그래프모델을 사용한다. 확장성이 더 용이하다 Neo4J, 알레그로그래프, 버투오소 저희가 앞으로 사용할 녀석은 Firebase 는 문서형(Document)에 해당합니다.
Firebase는 SQL(Structured Query Language)를 사용하지 않고 JSON(JavaScript Object Notation)방식의 문서를 사용하여 저장을 합니다 가장 이해하기 쉽게 말하면 JSON(JavaScript Object Notation을 Dictionary형태(Key-Value)를 사용하여 데이터를 주고 받을수 있도록 제공하고 있습니다. (JSON에 대한 설명 보기)
{ "key1" : "value", "key2" : 012341254, "key3" : false }보통은 위에 3가지 타입까지 인식이 가능합니다. 물론 배열도 가능합니다. 소수점도 역시 가능합니다. 단, JSON을 인식하는 타입에 대한 부분은 사용하는 라이브러리 혹은 플랫폼마다 상이 할 수는 있습니다. JSON의 기본은 인터넷에 많이 있습니다. 참고 하시길 바랍니다.
NoSQL은 3.5세대의 새로운 형태의 차세대데이터베이스입니다. 하지만 무조건 좋은건 아닙니다. 요즘에는 BigData시대로 확장성이 용이한 부분에서 사용이 되고 있고 아직도 몇몇 기업에서는 MySQL과 같은 SQL을 사용하는 곳도 있습니다. 각자에게 맞는 모델링을 찾아본다음 그후에 결정 하는것이 맞다고 봅니다.
일단 제가 Firebase를 사용 하면서 가장 힘들었던 부분은 NoSQL에 대한 모델링 부분 이었습니다. 기존에 RDBMS를 사용해왔었고, 익숙해져왔기 떄문에 처음 모델링을 할당시만 하더라도 이해가 안되는 부분이 많아서 고생을 많이 했습니다. 특히, 관계모델링인 (E-R)에 관점에서 생각하다보니 문제가 많았죠…
부질없는 짓이었습니다. 그냥 완전히 E-R관점이 아닌 다른 시각에서 출발하셔야 합니다. 즉, 각각의 관계는 없다라고 생각하고 출발하시면 조금은 출발하시기 쉬우실껍니다. (Join, Group등 생각을 버리세요)
3. Firebase 실시간 데이터베이스
실제로는 사용하는 부분에 있어서 JSON을 사용되지 않습니다. SDK에서는 Dictionary타입을 사용 하고 있습니다. 하지만 내부에서는 JSON 문서를 통해서 저장을 하고 있기 때문에 알고는 가야 하는 부분이라고 생각해서 간단하게 하고 넘어갔습니다. (사실 요즘에는 http통신간에 가장 많이 사용하고 있기도 합니다.)
조금 더 구조에 대해서 알아보고 가도록 하겠습니다.
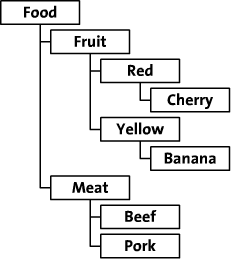
기본적으로는 부모자식관계를 가지고 Node형태의 방식으로 데이터구조가 쌓이게 되어 있습니다. Dictionary 구조로 설명을 하자면 키(부모) 값(자식)을 구조로 되어 있다고 생각 하시면 됩니다. 트리구조 라고 말씀드리면 더 쉽게 이해하시기 쉬울껍니다.
출처 : i-swear.com
게시판으로 예를 들도록 하겠습니다.
게시판에서 기본적으로 필요한 모델을 구성을 할때 필요한 값들이 있습니다.
최소한으로 놓고 본다면, 게시물고유값(번호), 제목, 작성자, 본문, 작성일, 수정일 까지 필요하다고 합시다.
게시번호 작성자 제목 본문 작성일 수정일 1 master [공지]첫 게시글 안녕하세요 20170419000000 20170419000000 2 user1 반갑습니다 ~ 제곧내 20170419000000 20170419000000 3 user2 뭐하는 곳일까요? 쓸떄없는 글? 20170419000000 20170419000000 대충 이렇게 데이터가 쌓여 있다고 합시다 (보기 편하게 테이블로 표현 했습니다)
이제는 실제로 파이어베이스에서는 어떻게 구조가 되는지 보도록 합시다.
{ "Board" : { "1" :{ "author" : "master", "title" : "[공지]첫 게시글", "body" : "안녕하세요", "createTime" : 20170419000000, "editTime" : 20170419000000 }, "2" : { "author" : "user1", "title" : "[반갑습니다 ~", "body" : "제곧내", "createTime" : 20170419000000, "editTime" : 20170419000000 }, "3" : { "author" : "user2", "title" : "뭐하는 곳일까요?", "body" : "쓸떄없는 글?", "createTime" : 20170419000000, "editTime" : 20170419000000 } } }이러한 형태로 계속 데이터가 쌓이게 되는 형태로 되어 있습니다.확실히 테이블로 보던 녀석과는 좀 다릅니다.
실제 파이어베이스의 프로젝트내부로 들어가면 보이는 형태는 그래픽으로 나와있습니다.
하지만 테이블 형태가 트리구조로 표현이 되어 있습니다.그렇기 때문에 ER관계도를 생각하시면 더 어렵습니다. 물론 JSON형태를 사용하기 때문에 배열형태도 사용이 가능합니다. 하지만 특별한 부분이 아니면 이러한 방식을 권해드리고 싶습니다.
이러한 문서형으로 되어 있기때문에 가장 힘든부분이 사실상은 JOIN과 특정 부분의 Sort가 힘듭니다.
보통 게시판을 모델링 할때는 관계형데이터베이스는 Primary Key 와 Forein Key를 가지고 관계를 지어줍니다.
하지만 NoSQL은 스키마가 없습니다. 그래서 관계에 대한 정의를 해줄수가 없습니다.
만약 1번 게시물에 댓글을 간단하게 표현한다면(Board노드는 생략)
{ "1" :{ "author" : "master", "title" : "[공지]첫 게시글", "body" : "안녕하세요", "createTime" : 20170419000000, "editTime" : 20170419000000, "reply" : { "1" : { "author" : "user3", "text" : "안녕하세요 영자님", "time" : 2017042140000 } } } }위에와 같은 형태가 되는 것이 맞습니다.
아니면 reply란 항목이 나와서 별도로 게시물의 번호값을 가지고 있던가 하는 방식이 맞을것 같네요
(여러명이서 작업을 할때는 나눠놓는것을 추천 드립니다. 혼동이 올수가 있습니다.)이제 어느정도 이해 하셨는지 모르겠네요?
이처럼 NoSQL와 Firebase 실시간데이터베이스에 대해서 간단하게 알아봤습니다.
다음 포스팅에는 기본사용법을 가지고 어떻게 사용하는지에 대해서 알려드리고자 합니다.
궁금하신 부분은 아래 댓글에 남겨주시면 제가 아는 방법한도에서 알려드리도록 하겠습니다.
아 깜빡하고 다루지 않은 부분이 있습니다. 권한에 관련된 부분인데요
이 방법은 그냥 링크로 대체를 하려고 합니다. 너무 설명이 잘 나와 있어서
그냥 읽어보시면 이해를 하실 정도 입니다. 이 부분은 사용하는데 있어서 중요한 부분이니 꼭 지나치지 마시고 읽어주시길 바랍니다.
-
[이론] 컴퓨터의 연산 와 운영체제
- 이 포스팅은 개인적으로 공부했던 자료를 조사하고 정리한 자료 입니다. 최대한 정확하게 작성하려고 하였습니다.
컴퓨터의 연산
전 포스팅에서 컴퓨터는 0과 1로 연산을 한다고 언급을 한적이 있다.
역시 그렇다 컴퓨터는 연산을 할때 2진법을 이용해서 계산을 한다. 그럼 컴퓨터는 0과 1을 어떻게 사용을 해서 연산을 하게 되는 것인가?
이번 포스팅은 컴퓨터가 하는 연산 방법중 가장 많이 쓰는 연산에 대해서 언급을 할까 한다.
컴퓨터의 연산은 CPU안에 있는 가산기(덧셈을 하는 논리회로)를 통해서 처리를 하게 된다.
일반적으로 우리가 생각하는 사칙연산(더하기,빼기,곱하기,나누기)을 컴퓨터는 덧셈으로만 처리를 한다.
갑자기 뜬금없이 왠 덧셈으로만 연산을 한다는게 무슨 소리일까 싶을 것 같다.
컴퓨터는 0과 1밖에 구분을 못하고 2진수를 이용한 연산 밖에 못한다.(설명은 쉽게 하기 위해서 4bit 기준으로 이야기를 하도록 할꼐요)
여기서 우리가 보고 가야 할것은 컴퓨터는 수를 어떻게 표현하지 그리고 음수는 또 어떻게 표현 하나가 중요하다.
컴퓨터는 비트의 가장 앞자리를 부호를 위한 자리로 사용한다. 즉, 음수와 양수를 구분하는 비트표현 1자리 3자리는 수를 표현한다 (4bit기준)
0000 은 10진수면 0이고 0001 은 1, 0010은 2 이렇게 연산이 되는데 1000은 과연 어떻게 나올까?
대부분 아마 8을 생각을 하겠지만 사실 연산을 해보면 -8이 찍힌다. ??? 뜬금없는 소리지 하겠지만 앞서 말했듯이
이 표로 설명을 하면 4비트 기준으로 첫째 1비트는 부호(양수는 0 음수는 1)을 표현하고 나머지는 수를 표현하도록 한것이다. 그렇기 때문에 저 값은 -8 값이 나오게 된다 1001 은 -1 이라고 보면 된다.
자 그럼 컴퓨터가 덧셈밖에 못하는 바보같은 녀석인데 어떻게 연산을 하게 되는 것인가? 의문이 들것이다.
예제) 3 + 2 = 5 0011 & 0010 ------------- 0101덧셈의 규칙 1) 1과 1일경우 한 자리수를 올린다 2) 1과 0일경우 1이 남는다 3) 비트 범위를 벗어날 경우 앞자리를 버린다
1 0 0 0 0 4비트 기준으로 연산을 하였을때 위에와 같이 1비트가 나오게 될경우 앞자리는 없애버리는 것이다.
자 다시 한번 연산을 해보도록 하자 1과 7을 덧셈을 하면 아래와 같이 나온다.
0001 1 & 0111 + 7 ----------- ------ 1000 - 8위와 같이 참으로 예쁘게(거지 같이) 계산이 된다. ?????? 이게 왠 (개소리)헛소리인가 싶겟지만 실제 컴퓨터는 연산을 위에 와 같이 연산을 해준다.
그이유는 맨 앞자리는 부호를 위한 비트이기 때문이다.
1 0 0 0 그렇다면 뺄셈은 과연 어떻게 할까?
역시 뺄셈도 덧셈을 통해서 연산을 한다
단 2의 보수를 사용해서 연산을 한다
즉 3 - 2 를 연산 하고자 한다면 3 + (-2) 로 하여서 계산을 하는 것이다.
0 0000 0 0000 1 0001 -1 1111 2 0010 -2 1010 3 0011 -3 1101 4 0100 -4 1100 5 0101 -5 1011 6 0110 -6 1010 7 0111 -7 1001 8 -8 1000 <2의 보수>
2의 보수 구하는 방법
3을 보수를 구하려면 현재 비트를 반전을 시킨다
0 0 1 1 (NOT)
1 1 0 0 반전한 수에 1을 더한다.
1 1 0 1 다시 연산을 한다면
0011 & 1101 ------------- 1 0000 = 0000(2) = 0(10)곱셈은 덧셈을 반복 나눗셈은 뺄셈을 반복 하는 방식으로 계산을 한다.
< 논리연산 / 자료출처 : 모두의마음 블로그 >
-
[이론] 컴퓨터란
** * 이 포스팅은 개인적으로 공부했던 자료를 조사하고 정리한 자료 입니다. 최대한 정확하게 작성하려고 하였습니다. **
컴퓨터란?
수학자들이 빠른 연산을 위해 만든 장치 = 계산기* 컴퓨터가 2진수를 쓰게 된 이유가 이때 당시 수학자들이 2진법을 사용 했기 때문이다.
2진법 이란?
-
이진법(二進法, binary)은 두 개의 숫자만을 이용하는 수 체계이다.
* 사람이 사용하는 0~9까지의 수를 십진법이라고 한다.
-
왜 10진법 이냐고 물어본다면 찾아보니 사람 손가락 갯수가 10개라서 라고 한다…(생각보다 단순한 논리였다)
1011(2) = 1 * (2^3) + 0 + 1 * (2) + 1 * (2^0) = 8 + 2 + 1 = 11(10) = B(16) 0xF32 = F32(16)= F * (16^2) + 3 * (16^1) + 2 * (16^0) = 15 * 32 + 3*16 + 2 = 3890진법은 여기서 이정도로 다루고 다시 차후 따로 포스팅 하도록 하겠습니다.
컴퓨터의 역사
컴퓨터라는 개념을 처음 고안한 사람은?
엘런 매티슨 튜링(Alan Mathieson Turing) 이란 수학자 양반이 2진법을 이용하면 빠른 계산을 할수 있지 않을까 라는 생각에서 고안해낸것이 컴퓨터이다.
즉, 인간이 아닌 기계를 이용해서 빠른 연산을 위해서 만든것이 컴퓨터 라는 것입니다.
첨언을 조금 하자면 컴퓨터 = 계산기 라는 개념인데 최초의 계산하는 기계는 파스칼 이란 사람이 만든 계산기에서 출발한다고 이야기를 하고 있다.
그래서 이 컨셉으로 따지면 최초의 컴퓨터는 파스칼이 만들었다라는게 정론이다. (누가 만들 건 사실 0과 1만 안썼어도……)
세대별 컴퓨터
-
1세대 컴퓨터
특징 : 엄청엄청 거대하다, 진공관을 사용한다.
대표적 1세대 컴퓨터 는 에니악(ENIAC) 이다.
<에니악(ENIAC) / 자료출처 : 위키피디아>
<진공관/자료출처:J Album>
* 썰풀기! 코딩하면서 버그를 잡는다의 출발이 여기서 나왔다. 진공관을 사용하기 때문에 열기도 엄청났고 내구성이 좋지 않았기 때문에 이 진공관을 교체하는 사람이 별도로 있기도 했다. 이 열기 때문에 벌레들이 살기 좋은 환경이 되자 여기서 알을 까는 일들이 즐비 해서 이것또한 고장의 원인이었기에 여기서 버그를 잡는다의 시작은 여기서 출발이 되었다고 한다. -
2세대컴퓨터
특징 : 트랜지스터, 1세대보다는 개선 되었지만 여전히 컴퓨터의 크기가 크다
<여러 종류의 트렌지스터 / 출처 : 위키피디아> -
3세대컴퓨터
특징 : 직접회로(IC), 이떄 부터 컴퓨터의 소형화가 이루어지기 시작함, 직접회로는 실제 크기는 아주 작기 때문에 소형화가 가능했다.
<직접회로 / 출처 : 위키피디아>
컴퓨터의 구성
컴퓨터는 크게 소프트웨어와 하드웨어로 나뉩니다
소프트웨어에는 응용소프트웨어 와 시스템소프트웨어 이렇게 두가지로 나뉘어 집니다.
응용소프트웨어는 OS(Operating System)위에서 실행 되는 모든 소프트웨어를 일컫고, 시스템소프트웨어로는 윈도우, OS X, Linux, Unix등 과 같은 운영체제, 로더, 장치드라이버, 컴파일러, 에셈블러, 링커, 유틸리티로 나눕니다.
시스템소프트웨어 응용소프트웨어 운영체제 게임 로더(Loader) 워드프로세스 장치드라이버 브라우저(사파리, 크롬, 파이어폭스 등) 컴파일러 OS 위에서 실행 되는 모든 프로그램들 에셈블러 링커 유틸리티 컴퓨터의 구조
컴퓨터를 알려면 대표적으로 사용하는 구조를 알아야 합니다. 그래야 어떻게 작동이 되는지 알고 이해하여 프로그래밍을 할 수 있습니다.
컴퓨터의 구조를 이야기를 하면 대표적 두가지 구조에 대해서 이야기 합니다. 하버드구조 와 폰노이만 구조를 이야기를 합니다. 두구조의 차이는 메모리를 어떻게 쓰냐에 따른 차이입니다.
하버드 구조
: 가장 큰 특징은 메모리를 명령어와 데이터를 나눠서 각각 사용한다는 것입니다.
위에 보시는 그림과 같은 구조로 데이터메모리와 명령어메모리로 물리적으로 분리되어서 따로 사용이 되고 있는것이 특징입니다. 하버드 구조의 경우에는 속도가 빠릅니다. 그 이유는 특정한 처리만을 위해서 사용하기 때문입니다. 그로 인해서 발생하는 문제는 비용이 많이 들게 된다는 것입니다.폰노이만 구조
: 명령어와 데이터 메모리를 같이 공유한다.
위에 있는 그림은 폰노이만 구조의 특징적 구조입니다. 하버드 구조와 달리 메모리를 하나로 공유를 하는 것이 특징입니다. 그렇기때문에 발생하는 문제는 메모리가 병목현상이 발생하게 되어 속도가 하버드에 비하여 느리다는 것이 단점입니다. 하지만 특정한 기능을 사용하기 위해서 설계를 해야하는 하버드와 달리 메모리에 올라가는 프로그램만 바꾸면 되므로 비용절감이 되어서 오늘날 가장 많이 사용하는 구조중에 하나 입니다.구분 하버드구조 폰노이만구조 장점 프로그램당하나의구조이므로속도가빠르다 하나의 구조로 여러가지 프로그램을 사용 할수 있다. 단점 프로그램이 변경이되면 회로도가 변경이되어야한다. 프로그램이 변경이되면 회로도가 변경이되어야한다. * 오늘날의 컴퓨터는 이 방법들 적제적소에 맞도록 설계하여 사용 합니다.
* 당시에는 컴퓨터의 비용이 어마 했기에 폰노이만을 더 선호하였습니다.
데이터의 표현
컴퓨터는 2진법을 사용 하는 기계이다.
그렇기 때문에 우리는 컴퓨터가 어떻게 연산을 하는지 알아야 하고 어떻게 해야 하는지 알아야만 컴퓨터에 대해서 이해 할 수 있다.
정수
: 자연수(0 1 2 3 4 … ) 와 음수 ( -1 -2 -3…) 로 이루어진 숫자
일상 생활에서 접할수 있는 숫자는 10진법 이다 ( 손가락이 10개 이기 때문에 10진법을 사용한다 )
앞서 언급 했듯이 2진수는 0과 1을 사용해서 비트(bit)를 표현을 한다. 1개당 1비트씩 8bit면 8개의 자리가 있는 것이다.
8bit는 숫자를 표현 할수 있는 가장 큰 값은 256 ( = 8bit = 1111 1111(2) ) 이다.
256(10) => 2 x 10^2 + 5 x 10^1 + 6 x 10^0 [10진수] * ^ 는 제곱을 의미한다 1011(2) => 1 x 2^3 + 0 x 2^2 + 1 x 2^1 + 1 x 2^0 = 11 [2진수] 0xBB(16) => 1011 1011(2) => 187(10)대표적인 진법들은 16진법, 10진법 8진법 2진법이 있다.
실수
: 유리수와 무리수를 포함한 수의 집합
General floating point ko.svg
< IEEE 754 / 자료출러 : 위키피디아>위의 그림은 실수의 표현 방식중 하나이다. (부동소수점 중 IEEE 754) 실수에는 부호,지수,가수로 표현을 하는데 가수 부분에는 2진수로 된 비트의 숫자가 표현이 된다. 지수에는 소수점의 위치를 표현 한다.
* 이러한 표기법을 사용하는 이유는 소수라는 것은 완전한 수가 아니기 때문에 표현하는데 분명 한계가 있기 마련이다. 그렇기 때문에 IEEE 754와 같은 표기 방법을 정의해서 이와 같이 쓰자라고 약속을 한것이다. 단점으로는 어느정도의 수를 잘라내고 사용하기 때문에 정확한 수가 아니게 된다라는 것이다.
문자
말그대로 사람이 사용하는 문자이다. 컴퓨터는 0과 1밖에 구분을 못하기 때문에 일정한 규칙을 만듬으로써 문자를 표현하도록 하엿다. 아스키코드( ASCII ), 유니코드, UTF-8등등의 방식이 있고 이러한 것들을 인코딩(Encoding) 이라 일컷는다. 인코딩은 문자 뿐만 아니라 영상, 음악 등 여러가지가 있다. 이러한 인코딩 방식을 만드는 이유는 나라 혹은 사람마다 쓰는 규격이 다르기 때문이다.
- 실제로 외부망으로 통신을 할때 이 인코딩을 맞추는 작업이 상당히 고역이다. 전송되는 과정에서 손실되는 것은 감안하고 해도 인코딩이라는것이 시스템에 따라서 사용하는 언어에 따라서 달라지는 경우도 있다.
참고자료링크
- https://ko.wikipedia.org/wiki/이진법
- https://ko.wikipedia.org/wiki/앨런_튜링
- https://ko.wikipedia.org/wiki/IEEE_754
참고링크는 보았던 사이트중 가장 괜찮은 사이트만 올렸습니다.
-